F1 Score - Balanced Accuracy And F1 Score Way To Be A Data Scientist / F1 score is a classification error metric used to evaluate the classification machine learning algorithms.
F1 Score - Balanced Accuracy And F1 Score Way To Be A Data Scientist / F1 score is a classification error metric used to evaluate the classification machine learning algorithms.. The f1 score can be interpreted as a weighted average of the precision and recall, where an f1 score reaches its best value at 1 and worst score at 0. The f1 score can be interpreted as a weighted average of the precision and recall, where an f1 score reaches its best value at 1 and worst score at 0. Therefore, this score takes both false positives and false negatives into account. # load libraries from sklearn.model_selection import cross_val_score from sklearn.linear_model import logisticregression from sklearn.datasets import make_classification. These examples are extracted from open source projects.
We will also understand the application of precision, recall and f1. These examples are extracted from open source projects. The f1 score can be interpreted as a weighted average of the precision and recall, where an f1 score reaches its best value at 1 and worst score at 0. F1 score is a classification error metric used to evaluate the classification machine learning algorithms. You will often spot them in academic papers where researchers use a higher.

You will often spot them in academic papers where researchers use a higher.
F1 score is based on precision and recall. # load libraries from sklearn.model_selection import cross_val_score from sklearn.linear_model import logisticregression from sklearn.datasets import make_classification. If you have a few years of experience in computer science or research, and you're interested in sharing that experience with the community. You will often spot them in academic papers where researchers use a higher. It considers both the precision and the recall of the test to compute the score. Intuitively it is not as easy to understand as accuracy. But first, a big fat warning: The f1 score can be interpreted as a weighted average of the precision and recall, where an f1 score reaches its best value at 1 and worst score at 0. Here is a detailed explanation of precision, recall and f1 score. Which model should i use for making predictions on future data? The following are 30 code examples for showing how to use sklearn.metrics.f1_score(). The relative the formula for the f1 score is The f1 score can be interpreted as a weighted average of the precision and recall, where an f1 score reaches its best value at 1 and worst score at 0.
It is primarily used to compare the performance of two classifiers. Firstly we need to know about the confusion matrix. The higher the f1 score the better, with 0 being the worst possible and 1 being the best. You will often spot them in academic papers where researchers use a higher. Why does a good f1 score matter?
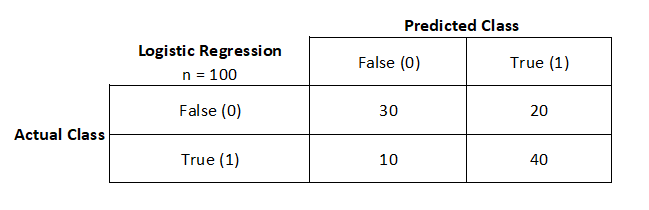
F1 score is a classification error metric used to evaluate the classification machine learning algorithms.
I have noticed that after training on same data gbc has higher accuracy score, while keras model has higher f1 score. From what i recall this is the metric present. Which model should i use for making predictions on future data? The f1 score can be interpreted as a weighted average of the precision and recall, where an f1 score reaches its best value at 1 and worst score at 0. The f1 score can be interpreted as a weighted average of the precision and recall, where an f1 score reaches its best value at 1 and worst score at 0. The relative the formula for the f1 score is It is calculated from the precision and recall of the test, where the precision is the number of correctly identified positive results divided by the number of all positive results. Evaluate classification models using f1 score. The following are 30 code examples for showing how to use sklearn.metrics.f1_score(). F1 score is based on precision and recall. You can vote up the ones you like or vote down. Here is a detailed explanation of precision, recall and f1 score. We will also understand the application of precision, recall and f1.
The relative the formula for the f1 score is It is calculated from the precision and recall of the test, where the precision is the number of correctly identified positive results divided by the number of all positive results. The following are 30 code examples for showing how to use sklearn.metrics.f1_score(). Firstly we need to know about the confusion matrix. From what i recall this is the metric present.
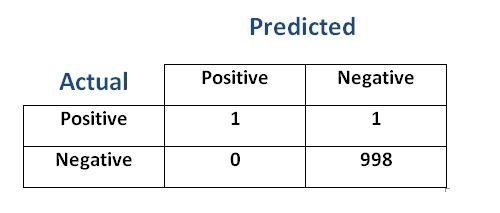
You can vote up the ones you like or vote down.
Here is a detailed explanation of precision, recall and f1 score. Last year, i worked on a machine learning model that suggests whether our. It is primarily used to compare the performance of two classifiers. It considers both the precision and the recall of the test to compute the score. Therefore, this score takes both false positives and false negatives into account. But first, a big fat warning: Mostly, it is useful in evaluating the prediction for binary classification of data. We're starting a new computer science area. The higher the f1 score the better, with 0 being the worst possible and 1 being the best. The relative the formula for the f1 score is You can vote up the ones you like or vote down. The following are 30 code examples for showing how to use sklearn.metrics.f1_score(). Why does a good f1 score matter?



Comments
Post a Comment